As in previous posts, for those of you less familiar with the differences and similarities between RDF and the Property Graph, I recommend you watch this talk I gave at Graph Connect San Francisco in October 2016.
In the previous post on this series, I showed the most basic way in which a portion of your graph can be exposed as RDF. That was identifying a node by ID or URI if your data was imported from an RDF dataset. In this one, I’ll explore a more interesting way by running Cypher queries and serialising the resulting subgraph as RDF.
The dataset
For this example I’ll use the Nortwind database that you can easily load in your Neo4j instance by running the following in your Neo4j browswer.
:play northwind graph
If you follow the step by step instructions you should get the graph built in no time. You’re ready then to run queries like “Get the detail of the orders by Rita Müller containing at least a dairy product”. Here is the cypher for it:
MATCH (cust:Customer {contactName : "Rita Müller"})-[p:PURCHASED]->(o:Order)-[or:ORDERS]->(pr:Product)
WHERE (o)-[:ORDERS]->()-[:PART_OF]->(:Category {categoryName:"Dairy Products"})
RETURN *
And this the resulting graph:

Serialising the output of a cypher query as RDF
The result of the previous query is a portion of the Nortwhind graph, a set of nodes and relationships that can be serialised as RDF using the neosemantics neo4j extension.
Once installed on your Neo4j instance, you’ll notice that the neosemantics extension includes a cypher endpoint /rdf/cypher (described here) that takes a cypher queryas input and returns the results serialised as RDF with the usual choice of serialisation format in the HTTP request.
The endpoint can be tested directly from the browser and will produce JSON-LD by default.
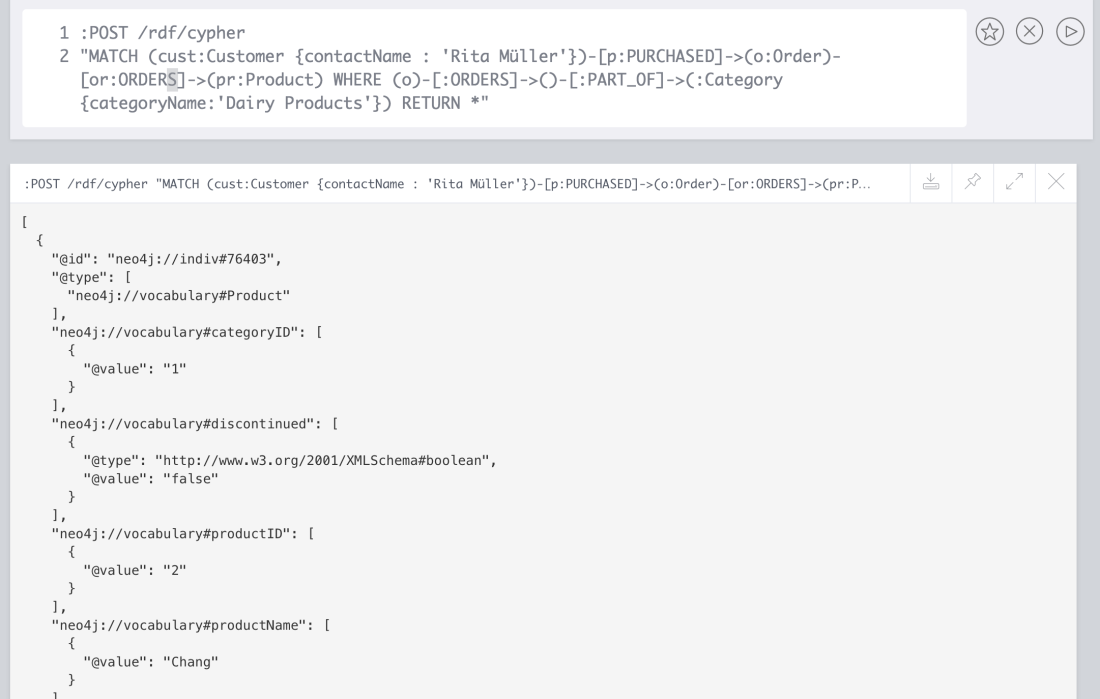
The uris of the resources in RDF are generated from the node ids in neo4j and in this first version of the LPG-to-RDF endpoint, all elements in the graph -RDF properties and types- share the same generic vocabulary namespace (It will be different if your graph has been imported from an RDF dataset as we’ll see in the final section).
Validating the RDF output on the W3C RDF Validation Service
A simple way of validating the output of the serialisation could be to load it into the W3C RDF validation service. It takes two simple steps:
Step one: Run your Cypher query on the rdf/cypyher endpoint selecting application/rdf+xml as serialization format on the Accept header of the http request. This is what the curl expresion would look like:
curl http://localhost:7474/rdf/cypher -H Accept:application/rdf+xml
-d "MATCH (cust:Customer {contactName : 'Rita Müller'})-[p:PURCHASED]->(o:OrdeERS]->(pr:Product) WHERE (o)-[:ORDERS]->()-[:PART_OF]->(:Category {categoryName:'Dairy Products'}) RETURN *"
This should produce something like this (showing only the first few rows):
<?xml version="1.0" encoding="UTF-8"?> <rdf:RDF xmlns:neovoc="neo4j://vocabulary#" xmlns:neoind="neo4j://indiv#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"> <rdf:Description rdf:about="neo4j://indiv#77511"> <rdf:type rdf:resource="neo4j://vocabulary#Customer"/> <neovoc:country rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Germany</neovoc:country> <neovoc:address rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Adenauerallee 900</neovoc:address> <neovoc:contactTitle rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Sales Representative</neovoc:contactTitle> <neovoc:city rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Stuttgart</neovoc:city> <neovoc:phone rdf:datatype="http://www.w3.org/2001/XMLSchema#string">0711-020361</neovoc:phone> <neovoc:contactName rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Rita Müller</neovoc:contactName> <neovoc:companyName rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Die Wandernde Kuh</neovoc:companyName> <neovoc:postalCode rdf:datatype="http://www.w3.org/2001/XMLSchema#string">70563</neovoc:postalCode> <neovoc:customerID rdf:datatype="http://www.w3.org/2001/XMLSchema#string">WANDK</neovoc:customerID> <neovoc:fax rdf:datatype="http://www.w3.org/2001/XMLSchema#string">0711-035428</neovoc:fax> <neovoc:region rdf:datatype="http://www.w3.org/2001/XMLSchema#string">NULL</neovoc:region> </rdf:Description> <rdf:Description rdf:about="neo4j://indiv#77937"> <neovoc:ORDERS rdf:resource="neo4j://indiv#76432"/> </rdf:Description> ...
I know the XML based format is pretty horrible but we need it because it’s the only one that the RDF validator accetps 😦
Step two: Go to the W3C RDF validation service page (https://www.w3.org/RDF/Validator/) and copy the xml from the previous step in the text box and select triples and graph in the display options. Hit Parse RDF and… you should get the list of 266 parsed triples plus a graphical representation of the RDF graph like this one:

Yes, I know, huge if we compare it to the original property graph but this is normal. RDF makes an atomic decomposition of every single statement in your data. In an RDF graph not only entities but also every single property produce a new vertex, leading to this explosion in the size of the graph.

That’s a slide from this talk at Graph Connect SF in Oct 2016 where I discussed that it’s normal that the number of triples in an RDF dataset is an order of magnitude bigger than the number of nodes in a LPG.
The portion of the Northwind graph returned by our example query is not an exception 19 nodes => 266 triples.
If the graph was imported from RDF…
So if your graph in Neo4j had been imported using the semantics.importRDF procedure (described in previous blog posts and with some examples) then you want to use the rdf/cypheronrdf endpoint (described here) instead. It works exactly in the same way, but uses the uris as unique identifiers for nodes instead of the ids.
If you’re interested on what this would look like, watch this space for part three of this series.
Takeaways
As in the previous post, the main takeaway is that it is pretty straightforward to offer an RDF “open standards compliant” API for publishing your graph while still getting the benefits of native graph storage and Cypher querying in Neo4j.

3 thoughts on “Neo4j is your RDF store (part 2)”